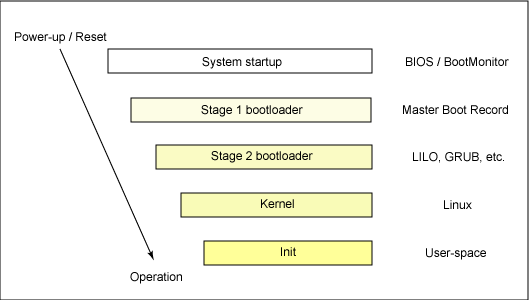
Booloaders on i386/x86_64
Before examining this code, you’ll notice three files in arch/x86/mm/, named init_32.c, init_64.c, and init.c. The file named init.c, is used by the main program entry point for Memory Management. Minimal Assembly is always required to boot hardware; however, most bootloaders switch to C as early as possible. As mentioned above, the hardware-enabled protection available in 32-bit mode allows for stack creation, and, ultimately, allows the bootloader to switch to C.
When the system is powered own, after BIOS integrity checks, the system will jump to a fixed location where control is given to the bootloader.
In arch/boot/header.S, you will see the address for the legacy Boot sector and load address. These addresses are fixed: all
x86 systems will jmp boot from this location. This file, header.S, contains the function assembly function start_of_setup:
which is used to start the system setup process. This function calls arch/x86/boot/main.c, which sets up the CPU, HEAP, and more. This is necessary to setup long, 32-bit, mode.
Next the bootloader transfers control to the code written in arch/x86/boot/compressed/head_64.S. As I stated above, x86 architectures cannot skip
booting to 32-bit mode. So, head_64.S includes the code necessary to setup 32-bit mode and them switch to 64-bit. If you were only booting to 32-bit mode,
and did not want to boot to 64-bit, then head_32.S would be used.
The kernel is decompressed here. The next call is to the code in arch/x86/kernel/head_64.S, which loads the kernel. Eventually, the MM code is run, starting with arch/x86/mm/init.c.
There’s a lot of code in arc/x86. To fully understand how all of it is used, you should examine the Makefile and Kbuild files. Here is a general overview to avoid confusion:
arch/x86 boot/ -> Strictly bootlaoder code entry/ -> Entry point code for handling interrupts, exceptions, and syscalls kernel/ -> For loading and setting up the Kernel kvm/ -> For kvm hardware virtualization support. mm -> For Memory Management net -> For Networking
The important thing to note is that, this code is in arch/x86 because it’s provides the mechanisms for direct interaction with hardware. These mechanisms are used by the kernel and other linux subsystems to interract with hardware. Because architecture’s are very different (different ISAs, features, etc.), the code in arch/*/ provides an interface of sorts, that is used by the kernel/subsystems (which are arch agnostic/independent). It’s also where the bootloader code is, which is used for booting.
For example, arch/x86/kernel includes the low-level code for the kernel, as well as abstractions that are used by the Kernel subystem code (i.e., linux/kernel) and other subs. For example, arch/x86/kernel/idt.c includes code for setting up the Interrupt descriptor table. It also has msr.c, which includes abstractions for writing to Model Specific Regsiter, control registers. The file irq.c, includes interrupt helpers such as those used for getting stats in /proc/interrupts, or acking a bad irq: interracting with the APIC (Advanced Programmable Interrupt Controller).
arch/x86/entry, contains entry points for handling interrupts. arch/x86/boot handles bootloading (the file head_32.S for loading the kernel is not in arch/x86/boot because it represents the end of bootloading. Once control is given to that program, the kernel is loaded, and it’s Linux city from that point on.)
Ther’s also arch/x86/mm, for Memory management and that’s where we’ll continue.
Memory Management from arch/x86/mm
Again, the behavior for mem_init(), which is defined in mm/mm_init.c with the __weak marker (or attribute((weak)) ), is overridden/defined by the mm code for each architecture. For x86, that’s arch/x86/mm/.
void __init mem_init(void)
{
after_bootmem = 1;
x86_init.hyper.init_after_bootmem();
/*
* Check boundaries twice: Some fundamental inconsistencies can
* be detected at build time already.
*/
#define __FIXADDR_TOP (-PAGE_SIZE)
#ifdef CONFIG_HIGHMEM
BUILD_BUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE > FIXADDR_START);
BUILD_BUG_ON(VMALLOC_END > PKMAP_BASE);
#endif
#define high_memory (-128UL << 20)
BUILD_BUG_ON(VMALLOC_START >= VMALLOC_END);
#undef high_memory
#undef __FIXADDR_TOP
#ifdef CONFIG_HIGHMEM
BUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE > FIXADDR_START);
BUG_ON(VMALLOC_END > PKMAP_BASE);
#endif
BUG_ON(VMALLOC_START >= VMALLOC_END);
BUG_ON((unsigned long)high_memory > VMALLOC_START);
test_wp_bit();
}
You see a few interesting lines in the beginning:
after_bootmem = 1;
x86_init.hyper.init_after_bootmem();
The struct x86_hyper_init, whose members are function pointers pointing to hypervisor init functions. The function pointer member seen in mem_init() has the handle init_after_bootmem().
I’m not going to go over this, but it’s worth noting the clear message that this function, mem_init(), is run after “bootmem” (i.e., after initial memory setup by the bootloader). So lets figure that out.
Initial Memory Boot (bootmem)
The function start_of_setup in arch/x86/boot/header.S ends with a calll instruction to main. The main symbol is from the main.c file in that same directory. Here is the body of that function with all but three calls removed:
void main(void)
{
detect_memory();
set_video();
go_to_protected_mode();
}
A function call is made to detect_memory, a symbol that’s defined in memory.c (within the same directory). Detect memory tail calls three other memory detection functsions:
void detect_memory(void)
{
detect_memory_e820();
detect_memory_e801();
detect_memory_88();
}
Each of these three functions passes a biosreg struct named ireg to the function initregs(), which simply initializes the segment registers. After initializing these registers, here is a breakdown of detect_memory_e820. I will share links for the others.
detect_memory_e820():
e820 is a shorthand alias for the x86 BIOS facility used to report memory map to the OS or bootloader. It is accessed using the int 15h interrupt call. The AX register value is set to 0xe820; once called, the usable memory address ranges are reported. Here is UEFI documentation on the Query System Address Map operation. (Note: the registers in the doc show EAX, but remember, AX is the low 16 bits of EAX)
As shown in the UEFI document linked above, ES:DI is the buffer pointer, CX is the buffer size and EDX is the signature ‘SMAP’ which is used by BIOS to verify the caller wants the system map information to be returned in ES:DI. EBX is for continuation; that is, get the next range of physical memory. EBX is the value of the previous call to the routine; if it’s the first call, then EBX must be zero. When EBX for the output register (oreg in this example) is zero, that execution was the last descriptor.
BIOS is not only used for integrity checks before the bootloader, it also exposes functions to the bootloader to get information discovered during BIOS checks.
The Linux kernel uses static struct boot_e820_entry struct for the buffer (e.g., static struct boot_e820_entry buf;), so CX can simply set to sizeof(buf) to get the size. Implementation is quite simple:
static void detect_memory_e820(void)
{
int count = 0;
struct biosregs ireg, oreg; // input/output register
struct boot_e820_entry *desc = boot_params.e820_table;
static struct boot_e820_entry buff;
initregs(&iregs);
ireg.ax = 0xe820;
ireg.cx = sizeof(buf);
ireg.edx = SMAP;
ireg.di = (size_t)&buf;
do {
intcall(0x15, &ireg, &oreg);
ireg.ebx = oreg.ebx;
// other code
*desc++ = buf;
count++;
} while (ireg.ebx && < ARRAY_SIZE(boot_params.e820_table));
boot_params.e820_entries = count;
}
Post memory dection, switch mode
After detect_memory() the main function continues calling the remaining functions in it’s body. The final call is to the function go_to_protected_mode(), which does many things, such as: enabling the A20 Gate, resetting the coprocessor, masking interrupts, and setting up the idt and gdt.
The function with symbol protected_mode_jump is called. This assembly function ends with a long jump to Lin_pm32 and that function ends by jumping to 32-bit entrypoint, which is in arch/x86/boot/compressed/head_32.S.
Here is the assembly for these functions.
SYM_FUNC_START_NOALIGN(protected_mode_jump)
movl %edx, %esi # Pointer to boot_params table
xorl %ebx, %ebx
movw %cs, %bx
shll $4, %ebx
addl %ebx, 2f
jmp 1f # Short jump to serialize on 386/486
1:
movw $__BOOT_DS, %cx
movw $__BOOT_TSS, %di
movl %cr0, %edx
orb $X86_CR0_PE, %dl # Protected mode
movl %edx, %cr0
# Transition to 32-bit mode
.byte 0x66, 0xea # ljmpl opcode
2: .long .Lin_pm32 # offset
.word __BOOT_CS # segment
SYM_FUNC_END(protected_mode_jump)
.code32
.section ".text32","ax"
SYM_FUNC_START_LOCAL_NOALIGN(.Lin_pm32)
# Set up data segments for flat 32-bit mode
movl %ecx, %ds
movl %ecx, %es
movl %ecx, %fs
movl %ecx, %gs
movl %ecx, %ss
# The 32-bit code sets up its own stack, but this way we do have
# a valid stack if some debugging hack wants to use it.
addl %ebx, %esp
# Set up TR to make Intel VT happy
ltr %di
# Clear registers to allow for future extensions to the
# 32-bit boot protocol
xorl %ecx, %ecx
xorl %edx, %edx
xorl %ebx, %ebx
xorl %ebp, %ebp
xorl %edi, %edi
# Set up LDTR to make Intel VT happy
lldt %cx
jmpl *%eax # Jump to the 32-bit entrypoint
SYM_FUNC_END(.Lin_pm32)
In the 32-bit entrypoint file arch/x86/boot/compressed/head_32.S, you’ll notice the symbol startup_32.
Read the comments here, they’re important (e.g., Startup happens at absolute address 0x00001000). This file is a successor to the original linux/boot/head.S with a copyright in 1991, 92, and 93.
I’ve written a lot on PLTs and GOTs. The GOT, Gobal Offset Table, is used in this file. Why? Remember PLT and GOT is used by ELF lazy loading to dynamically load code. The code is relocatable, thus, the relative address shown at compile time is different than load time. It will help to know about position dependence and independence PD/PIC. Simply put, the GOT is used for absolute relative offset address of this code. I believe the way this works is:
Position independent code cannot contain absolute virtual addresses. However, the GOT can hold absolute addresses in private data (i.e., .data section).
- This means PIC programs text (code in .text section) is still position-independent and sharable. A program references its GOT using Position-independent addressing and extracts absolute values.
- This essentially redirects position-independent refs to absolute.
- This means PIC programs text (code in .text section) is still position-independent and sharable. A program references its GOT using Position-independent addressing and extracts absolute values.
Elf Lazy linker uses the GOT
- When the linker is creating memory segments (correlating to sections) for loadable object files, it processes the relocation entries.
- The linker determines the symbol values, calculates their absolute addresses, and sets GOT entries to proper values.
- The linker does not know the absolute addresses at link time, but it does know the addresses of the memory segments, and calculates the absolute addresses of symbols contained therein.
- when the kernel loads the program, it maps the executable and shared objects into the processes virtual memory. The dynamic linker can see the memory segments because of these mappings.
- The dynamic linker can look at the symbol (that is to be loaded, dynamically) and knows the offset; that is, the distance between the memory segment (base) and the symbol. That is the absolute address that is then placed in GOT.
[!NOTE] For fun type readelf -r
on linux to see relocation information.
- To clarify this:
When the kernel loads a program, it maps the executable and its required shared objects into the process’s virtual memory space.
When a shared object is compiled, it produces a shared object file (.so), which is stored on disk. The file contains code and data along with symbol and relocation information, allowing only the required parts to be referenced and loaded at runtime.
When a process uses functions from a shared library, the dynamic linker performs lazy binding using the Procedure Linkage Table (PLT).
Example: if a program calls printf(), the dynamic linker will eventually locate the glibc shared object and the address of the printf function within it.
At compile time, the linker does not know the final runtime addresses of shared library functions. Instead, it populates relocation entries and creates PLT entries for dynamically linked symbols.
Each PLT entry initially points to a corresponding entry in the relocation table, which in turn references an entry in the Global Offset Table (GOT).
When the program is loaded and a dynamically linked symbol is called for the first time, execution jumps to the PLT entry, which transfers control to the dynamic linker.
The dynamic linker resolves the symbol, updates the corresponding GOT entry with the absolute address of the function in the shared object, and then transfers control to that function.
On subsequent calls, the PLT entry jumps directly to the resolved address in the GOT, avoiding further linker involvement.
After startup_32
After the jump to 32-bit long mode (i.e., protected mode), relocation is configured and then a jump to the label relocated and the compressed kernel is copied to the end of a buffer. Next, the bootloader extracts the compressed kernel and jumps to the kernel, both by calling extract_kernel. The compressed kernel is located at the end of the buffer used to hold the uncompressed kernel image (VO) and the execution environment (.bss, .brk). This ensures sufficient room to do the in-place decompression.
You’ll notice that extract_kernel, defined in arch/x86/boot/compressed/misc.c, is marked with asmlinkage.
asmlinkage __visible void *extract_kernel(void *rmode, unsigned char *output)
asmlinkage expands to: #define asmlinkage CPP_ASMLINKAGE __attribute__((regparm(0))) and is used to mark ALL syscalls, and many other functions within the kernel, including extract_kernel. Asmlinkage basically tells the compiler not to expect function args in registers. In accordance with the system V ABI, function args are normally placed in registers (usually limited to hte first 6). However, cases when these values need to be pushed to the stack. Lets explore this in the context of systemcalls.
When a userspace program triggers a syscall, the CPU jumps to a specific entry point in the kernel. In 64-bit mode, that entry point is entry_SYSCALL_64, defined in arch/x86/entry/entry_64.S. The snippet below shows what the registers look like upon entry. A syscall can be executed from userspace using syscall or int instructions. If your program operation requires kernel operation, the compiler will ensure relevant function args are pushed to the appropriate registers, as shown below, before the syscall instruction is used. If you choose to write assembly yourself to invoke a syscall, you must ensure registers are populated according to the syscalls expectation.
* Registers on entry:
* rax system call number
* rcx return address
* r11 saved rflags (note: r11 is callee-clobbered register in C ABI)
* rdi arg0
* rsi arg1
* rdx arg2
* r10 arg3 (needs to be moved to rcx to conform to C ABI)
* r8 arg4
* r9 arg5
* (note: r12-r15, rbp, rbx are callee-preserved in C ABI)
Before the kernel can execute c code, it must save the state of the userspace process so it can eventually return. This happens in Entry assembly. The kernel will push certain register values to the stack (for pt_regs struct), turn of IRQs, and call the syscall function do_syscall_64. The register values pushed onto the stack are used by do_syscall_64 to construct pt_regs.
[!NOTE] I’ve removed some code for brevity
SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
SYM_INNER_LABEL(entry_SYSCALL_64_after_hwframe, SYM_L_GLOBAL)
pushq %rax /* pt_regs->orig_ax */
/* IRQs are off. */
movq %rsp, %rdi
CLEAR_BRANCH_HISTORY
call do_syscall_64 /* returns with IRQs disabled */
Here, you can clearly see the pushq instructions used to push all vals needed to construct pt_regs, to the stack. You see USER DS/CS and PER_CPU_VAR. Register r11 (rflags), rcx (return address), and rax (syscall number) are also pushed. The users Data Segment, USER_DS will be the stack segment pointer in pt_reg and USER_CS will be code segment in pt_reg. This shows how pt_reg was a valuable context in eBPF and was used for certain eBPF program types.
Why Do this?
- Consistency and safety
- Using pt_regs, the kernel has a uniform way to access any register at any time. Very useful for debugging (ptrace) and signal handling.
- Avoiding register pressure & ABI mismatch
I’ll stop here, a lot of stuff is done in extract_kernel that you can look at if interested. After the kernel is extracted, the bootloader jumps to the extracted kernel. For 64-bit, after entering startup_32 and configuring relocatable memory, the bootloader prepares for 64-bit mode by enabling PAE, building 4GB boot pagetable, initialize multi-level page tables, then jumps to 64-bit mode, startup_64.
in 64-bit mode, segments and relocatable memory is setup again, then kernel is extracted.
Whether if 32-bit the jump is to the startup in arch/x86/kernel/head_32.S, else arch/x86/kernel/head_64.S for 64-bit. There are two startup labels in kernel/head_64.S. The first is an entry point exclusively for initial boot and the second is used by initial boot (transition from first label instructions using physical addresses) and the second from virtual address space using trampoline.S
When transitioning to secondary_startup_64 from startup_64 (i.e., initial booting) startup_64 will jump to a secondary label within secondary_startup_64 to skip repeating some tasks already done in startup_64. I’m not going to go through secondary_startup_64. At the end of that label body, is the code to jump to C code, the initial code which means the kernel is fully loaded and setup of kernel for 64-bit mode (i.e., hardware initialize, stack setup). There’s still more setup.
.Ljump_to_C_code:
xorl %ebp, %ebp # clear frame pointer
ANNOTATE_RETPOLINE_SAFE
callq *initial_code(%rip)
ud2
Later
SYM_DATA(initial_code, .quad x86_64_start_kernel)
Let’s take a look at call stack, starting with x86_64_start_kernel in arch/x86/kernel/head64.c:
asmlinkage __visible void __init __noreturn x86_64_start_kernel(char * real_mode_data)
void __init __noreturn x86_64_start_reservations(char *real_mode_data)
void start_kernel(void)
...
mm_core_init()
start_kernel is worth copy; however, it’s so large that I’ll do this in another file. As shown above, one of the calls is within kernel_start is mm_core_init(), which begins initialization of memory manager.
Interensting note on the order of initialization for cgroup related components.
cpuset_init();
mem_cgroup_init();
cgroup_init();
I see that mem_cgroup_init() is it’s own seperate initialization routine. cGroup is based on the original cpuset subsystem.
Here’s the stack canary:
/* These make use of the fully initialized rng */
kfence_init();
boot_init_stack_canary();